

**Note: The content in this article is only for educational purposes and understanding of cybersecurity concepts. It should enable people and organizations to have a better grip on threats and know how to protect themselves against them. Please use this information responsibly.**
Sitemaps and robots.txt are the two simple ways through which content can be discovered on websites and web applications. While primarily used to assist search engines attempting to index a site, sitemaps and robots.txt can be valuable methods for those wishing to better understand the structure of a site without the use of specialized tools.
Sitemaps
The sitemap protocol is a document that provides information about pages and files on a site and the relationships between them. It is provided by the website and typically contains links to each available section of the site. A simple sitemap is typically formatted in XML.

- <urlset> is a reference to which version of the sitemap protocol is being used.
- <url> denotes each location of one single URL with the specific link being provided inside <loc>.
Sitemaps can typically be accessed by appending /sitemap or /sitemap.xml to a website’s URL.
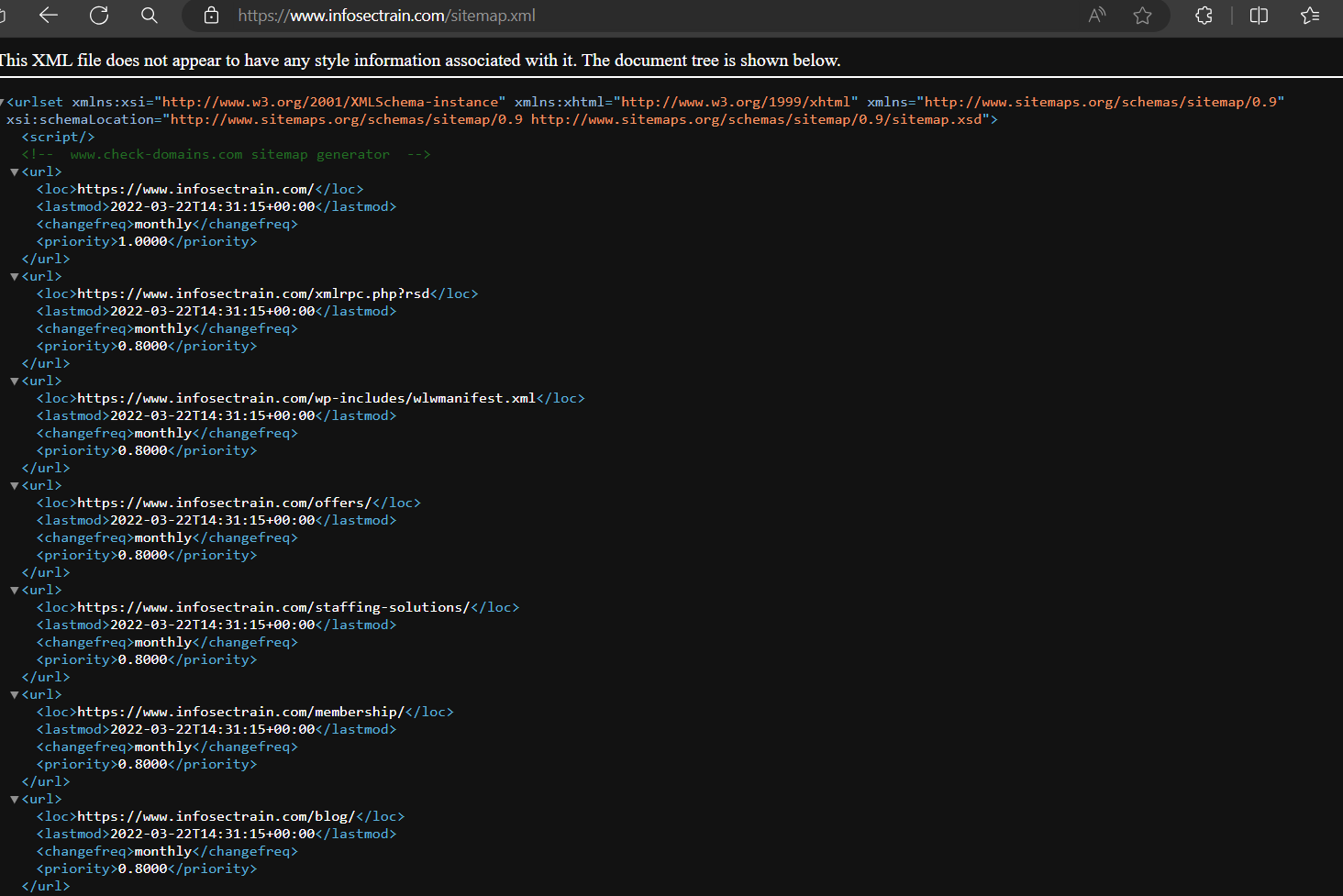
Sitemap of Infosectrain can be accessed by appending /sitemap.xml to the url.
Target link : infosectrain.com/sitemap.xml
Robots.txt
While sitemaps are used to aid in discovering content and sections of websites, robots.txt is a standard that defines which areas of a website should or should not be scanned or accessed by web crawlers and scanners, which are referred to as robots.
Robots.txt is a text file that site owners will place on their website to instruct web robots (usually search engine crawlers) which pages to crawl, and index, on a website. In these files, a deny or disallow directive informs the search engine that the site’s author/owner doesn’t want that resource to appear in a search engine or to be indexed.
Unfortunately, using robots.txt isn’t an official standard, and there are no assurances that a web crawler actually adheres to the requests in a robots.txt file. However, crawlers used by the most popular search engines (such as Google and Bing) do honor these requests, and will not index resources included in a disallow directive.
A basic robot.txt example can be seen below.
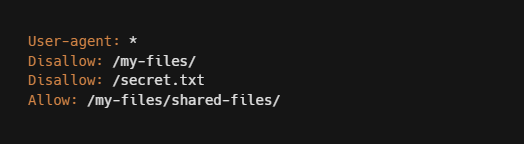
- User-agent defines what type of robot the rule applies to. In this example, the user-agent field contains a wildcard character (*) which signifies that this robots.txt is for all crawlers.
- Disallow specifies which path should not be accessed. In the above example, web robots are disallowed to access the /secret.txt path.
- Allow directive will request the subdirectories to be indexed by search engines. In the above example, the site owner wants resources in /my-files/shared-files to be available via search engines. Using (/) means that all web crawlers are permitted to access and crawl the entire website.
Robots.txt files are always found by appending /robots.txt to a website’s domain name.
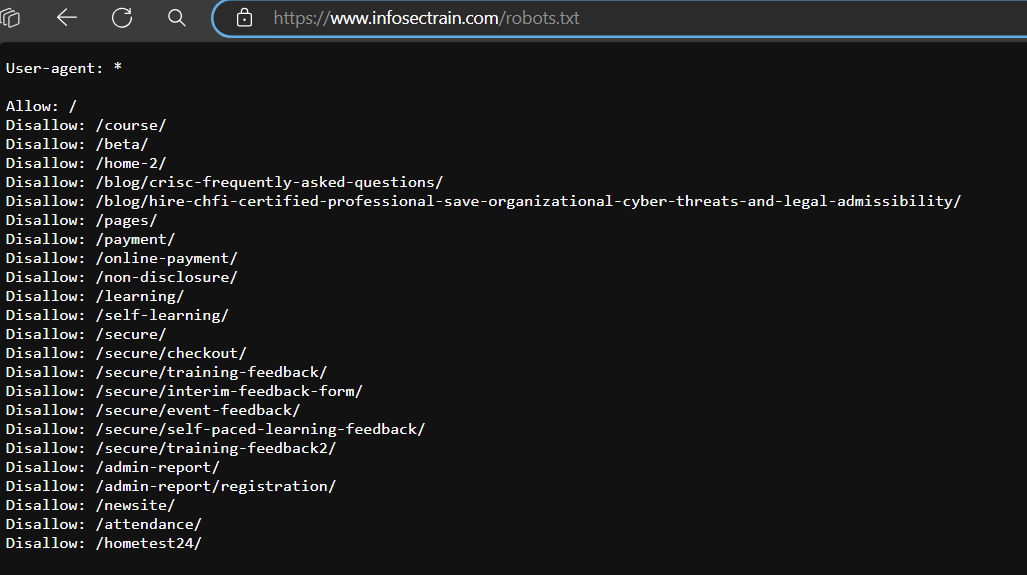
Robots.txt of Infosectrain can be accessed by appending /robots.txt to the url.
Target link : infosectrain.com/robots.txt
From a pentester perspective, it’s important to test and inspect both the sitemap or robots.txt file when:
- Sitemap updates have been made
- Robots.txt updates have been made
So to conclude, Sitemap.xml helps search engines index your site’s pages efficiently, while robots.txt directs search engine crawlers on which pages to access or avoid. Both are essential for optimizing website visibility and controlling crawler behavior.
Caught feelings for cybersecurity? It’s okay, it happens. Follow us on LinkedIn and Instagram to keep the spark alive.



