Decision trees are a supervised learning technique used in machine learning for classification and prediction tasks. They create a model based on labelled data i.e. past data with known outcomes, which can then be used for new data that has not been seen before.
Structure of Decision Tree
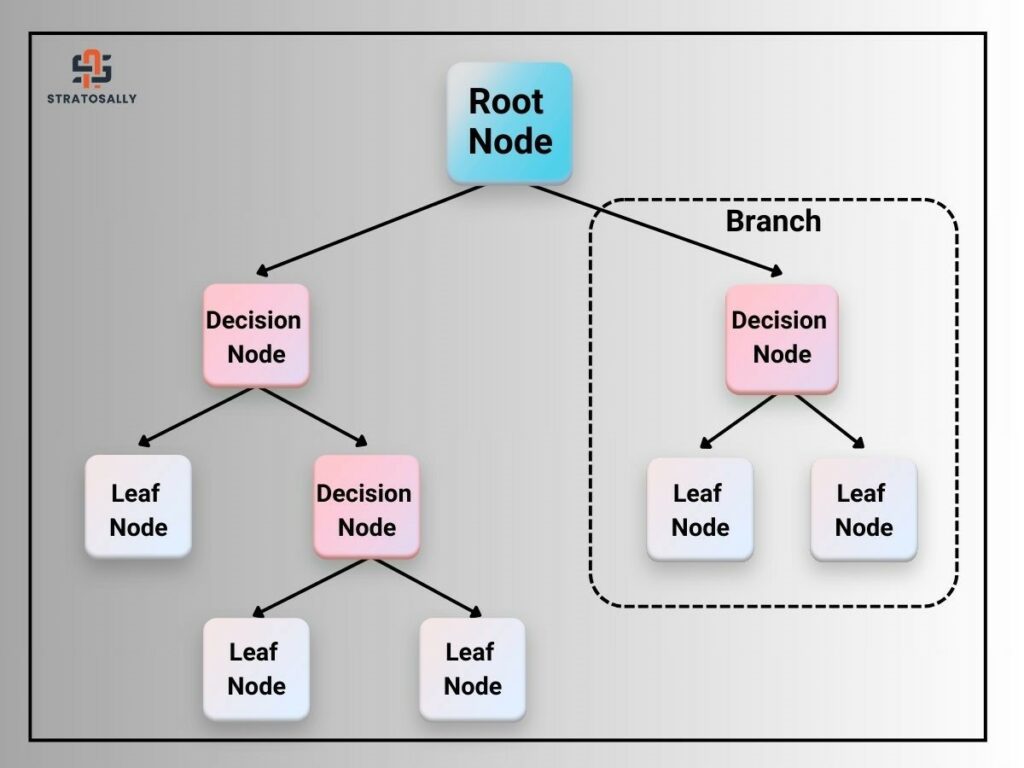
A decision tree is structured like an upside-down tree, starting with a single point called the root node. Then, it continues to branch out by splitting to create sub-nodes. It finally reaches the leaf node.
Root Node: The first node where all the data is fed.
Decision nodes: These nodes are situated at the point where a split has occurred and continue splitting into sub-nodes.
Leaf nodes: These nodes are the end of the branches. Each leaf node eventually produces an outcome or classification.
By following the tree and answering each question node, classification or prediction of the new data points can be pursued.
The Learning Process: Phishing Email Classification
Let’s see how a decision tree is built by classifying phishing emails:
Creation of Root Node
Starting point: We begin with a dataset of emails tagged as “phishing” or “legitimate.”
Initial split: The first condition picked by the algorithm could be, “Does the email have a URL?”
Left child: Emails containing URLs
Right child: Emails without URLs
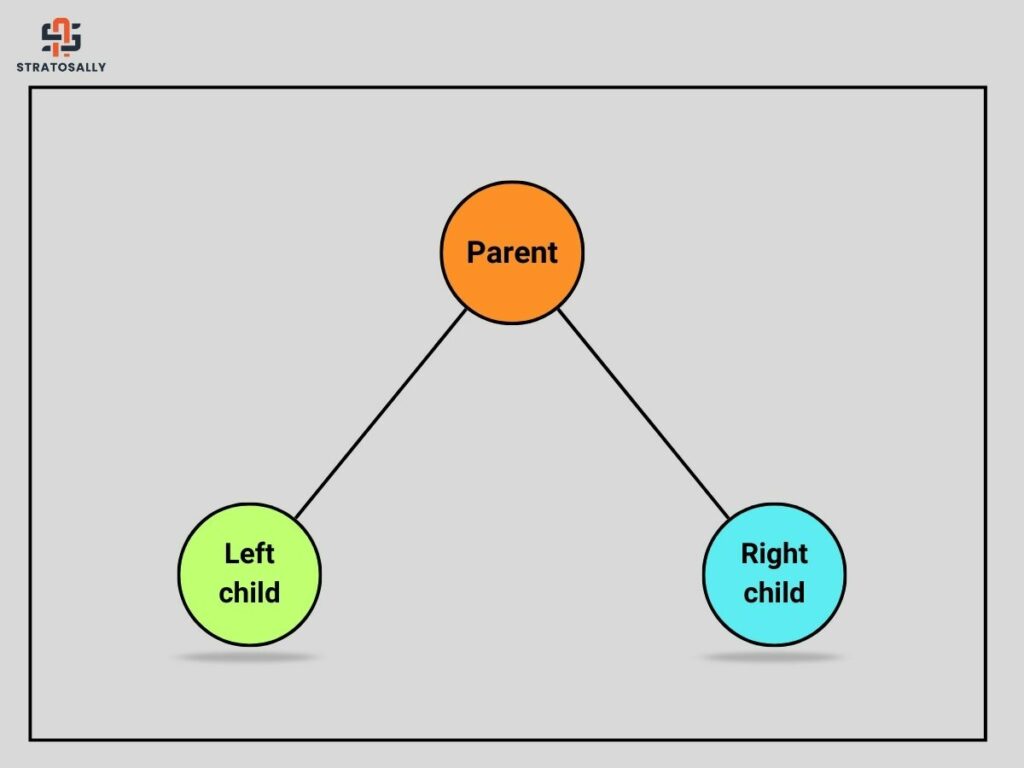
Recursive partitioning: Now, given the left child emails that contain URLs, the second condition can be:-
“Is the URL different than what was shown within the text?”
Yes: It will more likely be a phishing mail.
No: It needs further investigation.
For the right child to the node for emails without URLs, the next question that could be asked is, “Does the email ask the user for any personal information?”
Yes: It could be phishing
No: More likely to be legitimate
Continuous Refining: The tree continues to expand with even more specific conditions. For example:
“Is the sender’s email matching their claimed organization?”
“Is there poor spelling or grammar in the email?”
“Is urgent action being requested of the email?
Each of these conditions will further subdivide the emails into smaller-sized, homogeneous groups.
Leaf Node Creation:
It will stop the recursion when:
- One node contains only one class of e-mails, that is, all phishing or all legitimate.
- The required tree depth is reached.
- The number of e-mails flowing through a node is less than a threshold.
Classification of New E-mails
A new incoming e-mail, to be classified, would flow down the tree from the root to the leaf. At each node, the email attributes determine which branch to follow. The class phishing or legit will depend on what leaf it falls into.
In that way, a decision tree can learn from the complex patterns of e-mail characteristics where phishing could be differentiated from legitimate communications. The resultant tree provides an understandable and interpretable path for every classification decision. Hence, the explainability and transparency of this ML algorithm are high, making it easier for analysts to understand and justify the model’s working.
Implementing Decision Tree Phishing Email Detector Using Python
We will implement this project in Google Colab.
The email dataset has been taken from the UCI Machine Learning Repository. We will upload this to Google Colab.
Below is a screenshot of the dataset used:-


30 parameters have been used in the dataset.
As computing machines only understand numbers, yes and no are written as 1 and -1.
Now, we will import the necessary libraries:-

The decision tree function is present in the sci-kit learn library.

The function to read the datasets is present in the NumPy library.

We will then split our data for training and testing. As a decision tree is a supervised machine learning algorithm, the final output will be based on labelled data whose output is known.

Now, this is where the decision tree comes into play:-

Finally, we check the accuracy of the algorithm:-
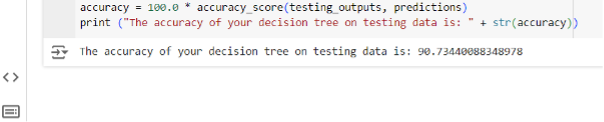
Therefore, the phishing email detector has been implemented with a satisfactory accuracy rate of 90.7%. This rate is higher than that obtained with logistic regression for the same dataset.
Caught feelings for cybersecurity? It’s okay, it happens. Follow us on LinkedIn and Instagram to keep the spark alive.